

You must log in or # to comment.
Bayesian purist cope and seeth.
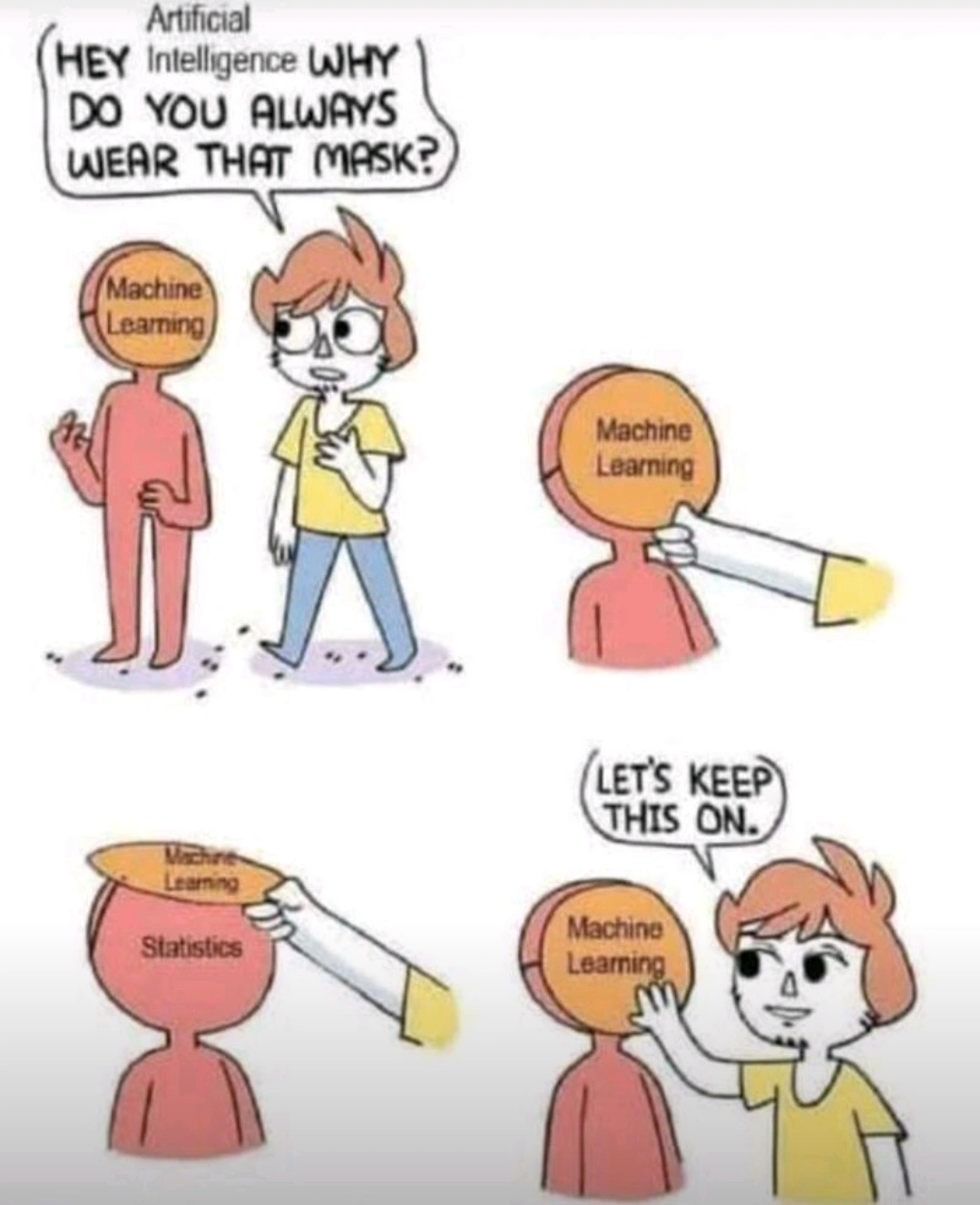
Most machine learning is closer to universal function approximation via autodifferentiation. Backpropagation just lets you create numerical models with insane parameter dimensionality.
I like your funny words, magic man.
erm, in english, please !
Universal function approximation - neural networks.
Auto-differentiation - algorithmic calculation of partial derivatives (aka gradients)
Backpropagation - when using a neural network (or most ML algorithms actually), you find the difference between model prediction and original labels. And the difference is sent back as gradients (of the loss function)
Parameter dimensionality - the “neurons” in the neural network, ie, the weight matrices.
If thats your argument, its worse than Statistics imo. Atleast statistics have solid theorems and proofs (albeit in very controlled distributions). All DL has right now is a bunch of papers published most often by large tech companies which may/may not work for the problem you’re working on.
Universal function approximation theorem is pretty dope tho. Im not saying ML isn’t interesting, some part of it is but most of it is meh. It’s fine.
A monad is just a monoid in the category of endofunctors, after all.
No, no, everyone knows that a monad is like a burrito.
(Joke is referencing this: https://blog.plover.com/prog/burritos.html )
So what you’re saying is that if you put a burrito inside a burrito it’s still a burrito?
Any practical universal function approximation will go against entropy.
deleted by creator
pee pee poo poo wee wee
Eh. Even heat is a statistical phenomenon, at some reference frame or another. I’ve developed model-dependent apathy.
Ftfy

Yes, this is much better because it reveals the LLMs are laundering bias from a corpus of dimwittery.
Inb4 AI suggesting to put glue on pizza
The meme would work just the same with the “machine learning” label replaced with “human cognition.”
Have to say that I love how this idea congealed into “popular fact” as soon as peoples paychecks started relying on massive investor buy in to LLMs.
I have a hard time believing that anyone truly convinced that humans operate as stochastic parrots or statistical analysis engines has any significant experience interacting with others human beings.
Less dismissively, are there any studies that actually support this concept?
Speaking as someone whose professional life depends on an understanding of human thoughts, feelings and sensations, I can’t help but have an opinion on this.
To offer an illustrative example
When I’m writing feedback for my students, which is a repetitive task with individual elements, it’s original and different every time.
And yet, anyone reading it would soon learn to recognise my style same as they could learn to recognise someone else’s or how many people have learned to spot text written by AI already.
I think it’s fair to say that this is because we do have a similar system for creating text especially in response to a given prompt, just like these things called AI. This is why people who read a lot develop their writing skills and style.
But, really significant, that’s not all I have. There’s so much more than that going on in a person.
So you’re both right in a way I’d say. This is how humans develop their individual style of expression, through data collection and stochastic methods, happening outside of awareness. As you suggest, just because humans can do this doesn’t mean the two structures are the same.
Idk. There’s something going on in how humans learn which is probably fundamentally different from current ML models.
Sure, humans learn from observing their environments, but they generally don’t need millions of examples to figure something out. They’ve got some kind of heuristics or other ways of learning things that lets them understand many things after seeing them just a few times or even once.
Most of the progress in ML models in recent years has been the discovery that you can get massive improvements with current models by just feeding them more and data. Essentially brute force. But there’s a limit to that, either because there might be a theoretical point where the gains stop, or the more practical issue of only having so much data and compute resources.
There’s almost certainly going to need to be some kind of breakthrough before we’re able to get meaningful further than we are now, let alone matching up to human cognition.
At least, that’s how I understand it from the classes I took in grad school. I’m not an expert by any means.
I would say that what humans do to learn has some elements of some machine learning approaches (Naive Bayes classifier comes to mind) on an unconscious level, but humans have a wild mix of different approaches to learning and even a single human employs many ways of capturing knowledge, and also, the imperfect and messy ways that humans capture and store knowledge is a critical feature of humanness.
I think we have to at least add the capacity to create links that were not learned through reasoning.
The difference in people is that our brains are continuously learning and LLMs are a static state model after being trained. To take your example about brute forcing more data, we’ve been doing that the second we were born. Every moment of every second we’ve had sound, light, taste, noises, feelings, etc, bombarding us nonstop. And our brains have astonishing storage capacity. AND our neurons function as both memory and processor (a holy grail in computing).
Sure, we have a ton of advantages on the hardware/wetware side of things. Okay, and technically the data-side also, but the idea of us learning from fewer examples isn’t exactly right. Even a 5 year old child has “trained” far longer than probably all other major LLMs being used right now combined.
The big difference between people and LLMs is that an LLM is static. It goes through a learning (training) phase as a singular event. Then going forward it’s locked into that state with no additional learning.
A person is constantly learning. Every moment of every second we have a ton of input feeding into our brains as well as a feedback loop within the mind itself. This creates an incredibly unique system that has never yet been replicated by computers. It makes our brains a dynamic engine as opposed to the static and locked state of an LLM.
Contemporary LLMs are static. LLMs are not static by definition.
Could you point me towards one that isn’t? Or is this something still in the theoretical?
I’m really trying not to be rude, but there’s a massive amount of BS being spread around based off what is potentially theoretically possible with these things. AI is in a massive bubble right now, with life changing amounts of money on the line. A lot of people have very vested interest in everyone believing that the theoretical possibilities are just a few months/years away from reality.
I’ve read enough Popular Science magazine, and heard enough “This is the year of the Linux desktop” to take claims of where technological advances are absolutely going to go with a grain of salt.
Remember that Microsoft chatbot that 4chan turned into a nazi over the course of a week? That was a self-updating language model using 2010s technology (versus the small-country-sized energy drain of ChatGPT4)
But they are. There’s no feedback loop and continuous training happening. Once an instance or conversation is done all that context is gone. The context is never integrated directly into the model as it happens. That’s more or less the way our brains work. Every stimulus, every thought, every sensation, every idea is added to our brain’s model as it happens.
This is actually why I find a lot of arguments about AI’s limitations as stochastic parrots very shortsighted. Language, picture or video models are indeed good at memorizing some reasonable features from their respective domains and building a simplistic (but often inaccurate) world model where some features of the world are generalized. They don’t reason per se but have really good ways to look up how typical reasoning would look like.
To get actual reasoning, you need to do what all AI labs are currently working on and add a neuro-symbolic spin to model outputs. In these approaches, a model generates ideas for what to do next, and the solution space is searched with more traditional methods. This introduces a dynamic element that’s more akin to human problem-solving, where the system can adapt and learn within the context of a specific task, even if it doesn’t permanently update the knowledge base of the idea-generating model.
A notable example is AlphaGeometry, a system that solves complex geometry problems without human demonstrations and insufficient training data that is based on an LLM and structured search. Similar approaches are also used for coding or for a recent strong improvement in reasoning to solve example from the ARC challenge..
I’d love to hear about any studies explaining the mechanism of human cognition.
Right now it’s looking pretty neural-net-like to me. That’s kind of where we got the idea for neural nets from in the first place.
It’s not specifically related, but biological neurons and artificial neurons are quite different in how they function. Neural nets are a crude approximation of the biological version. Doesn’t mean they can’t solve similar problems or achieve similar levels of cognition , just that about the only similarity they have is “network of input/output things”.
deleted by creator
Past results are no guarantee of future performance.
But claims of what future performance will be as given by people with careers, companies, and life changing amounts of money on the line are also no guarantee either.
The world would be a very different place if technology had advanced as predicted not even ten years ago.
deleted by creator
I’d love to hear about any studies explaining the mechanism of human cognition.
You’re just asking for any intro to cognitive psychology textbook.
Ehhh… It depends on what you mean by human cognition. Usually when tech people are talking about cognition, they’re just talking about a specific cognitive process in neurology.
Tech enthusiasts tend to present human cognition in a reductive manor that for the most part only focuses on the central nervous system. When in reality human cognition includes anyway we interact with the physical world or metaphysical concepts.
There’s something called the mind body problem that’s been mostly a philosophical concept for a long time, but is currently influencing work in medicine and in tech to a lesser degree.
Basically, it questions if it’s appropriate to delineate the mind from the body when it comes to consciousness. There’s a lot of evidence to suggest that that mental phenomenon are a subset of physical phenomenon. Meaning that cognition is reliant on actual physical interactions with our surroundings to develop.
If by “human cognition” you mean "tens of millions of improvised people manually checking and labeling images and text so that the AI can pretend to exist," then yes.
If you mean “it’s a living, thinking being,” then no.
My dude it’s math all the way down. Brains are not magic.
deleted by creator
We don’t need to understand cognition, nor for it to work the same as machine learning models, to say it’s essentially a statistical model
It’s enough to say that cognition is a black box process that takes sensory inputs to grow and learn, producing outputs like muscle commands.
You can abstract everything down to that level, doesn’t make it any more right.
Yes, that’s physics. We abstract things down to their constituent parts, to figure out what they are made up of, and how they work. Human brains aren’t straightforward computers, so they must rely on statistics if there is nothing non-physical (a “soul” or something).
I’m not saying we understand the brain perfectly, but everything we learn about it will follow logic and math.
deleted by creator
I agree experience is incalculable but not because it is some special immaterial substance but because experience just is objective reality from a particular context frame. I can do all the calculations I want on a piece of paper describing the properties of fire, but the paper it’s written on won’t suddenly burst into flames. A description of an object will never converge into a real object, and by no means will descriptions of reality ever become reality itself. The notion that experience is incalculable is just uninteresting. Of course, we can say the same about the wave function. We use it as a tool to predict where we will see real particles. You also cannot compute the real particles from the wave function either because it’s not a real entity but a description of relationships between observations (i.e. experiences) of real things.
(working with the assumption we mean stuff like ChatGPT) mKay… Tho math and logic is A LOT more than just statistics. At no point did we prove that statistics alone is enough to reach the point of cognition. I’d argue no statistical model can ever reach cognition, simply because it averages too much. The input we train it on is also fundamentally flawed. Feeding it only text skips the entire thinking and processing step of creating an answer. It literally just take texts and predicts on previous answers what’s the most likely text. It’s literally incapable of generating or reasoning in any other way then was already spelled out somewhere in the dataset. At BEST, it’s a chat simulator (or dare I say…language model?), it’s nowhere near an inteligence emulator in any capacity.
This is exactly how I explain the AI (ie what the current AI buzzword refers to) tob common folk.
And what that means in terms of use cases.
When you indiscriminately take human outputs (knowledge? opinions? excrements?) as an input, an average is just a shitty approximation of pleb opinion.or stolen data
**AND stolen data
Its curve fitting
But it’s fitting to millions of sets in hundreds of dimensions.
iT’s JuSt StAtIsTiCs

But it is, and it always has been. Absurdly complexly layered statistics, calculated faster than a human could.
This whole “we can’t explain how it works” is bullshit from software engineers too lazy to unwind the emergent behavior caused by their code.
I agree with your first paragraph, but unwinding that emergent behavior really can be impossible. It’s not just a matter of taking spaghetti code and deciphering it, ML usually works by generating weights in something like a decision tree, neural network, or statistical model.
Assigning any sort of human logic to why particular weights ended up where they are is educated guesswork at best.
You know what we do in engineering when we need to understand a system a lot of the time? We instrument it.
Please explain why this can’t be instrumented. Please explain why the trace data could not be analtzed offline at different timescales as a way to start understanding what is happening in the models.
I’m fucking embarassed for CS lately.
… but they just said that it can. You check it, and you will receive gibberish. Congrats, your value is .67845278462 and if you change that by .000000001 in either direction things break. Tell me why it ended up at that number. The numbers, what do they mean?
It’s not always as simple as measuring an observable system or simulating the parameters the best you can. Lots of parameters + lots of variables = we have a good idea how it should go, we can get close, but don’t actually know. That’s part of why emergent behavior and chaos theory are so difficult, even in theoretically closed systems.
That field is called Explainable AI and the answer is because that costs money and the only reason AI is being used is to cut costs
☝️
Thank you. I am fucking exhausted from hearing people claim these things are somehow magically impossible when the real issue is cost.
Computers and technology are amazing, but they are not magic. They are the most direct piece of reality where you can reliably say that every single action taken can be broken into discrete steps, even if that means tracing individual CPU operations on data registers like an insane person.
But it is, and it always has been. Absurdly complexly layered statistics, calculated faster than a human could.
Well sure, but as someone else said even heat is statistics. Saying “ML is just statistics” is so reductionist as to be meaningless. Heat is just statistics. Biology is just physics. Forests are just trees.
It’s like saying a jet engine is essentially just a wheel and axle rotating really fast. I mean, it is, but it’s shaped in such a way that it’s far more useful than just a wheel.
Yeah, but the critical question is: is human intelligence statistics?
Seems no, to me: a human lawyer wouldn’t, for instance, make up case law that doesn’t exist. AI has done that one already. If it had even the most basic understanding of what the law is and does, it would have known not to do that.
This shit is just megahal on a gpu.
Seems no, to me: a human lawyer wouldn’t, for instance, make up case law that doesn’t exist. AI has done that one already. If it had even the most basic understanding of what the law is and does, it would have known not to do that.
LLMs don’t have an understanding of anything, but that doesn’t mean all AI in perpetuity is incapable of having an understanding of eg. what the law is. Edit: oh and also, it’s not like human lawyers are incapable of mistakenly “inventing” case law just by remembering something wrong.
As to whether human intelligence is statistics, well… our brains are neural networks, and ultimately neural networks – whether made from meat or otherwise – are “just statistics.” So in a way I guess our intelligence is “just statistics”, but honestly the whole question is sort of missing the point; the problem with AI (which right now really means LLMs) isn’t the fact that they’re “just statistics”, and whether you think human intelligence is or isn’t “just statistics” doesn’t really tell you anything about why our brains perform better than LLMs
People confabulate all the time.
False memories can also be deliberately created. Here’s a classic: https://www.washington.edu/news/2001/06/11/i-tawt-i-taw-a-bunny-wabbit-at-disneyland-new-evidence-shows-false-memories-can-be-created/
Seems no, to me: a human lawyer wouldn’t, for instance, make up case law that doesn’t exist
You’ve never seen someone misremember something? The reason human lawyers don’t usually get too far with made-up case law is because they have reference material and they know to go back to it. Not because their brains don’t make stuff up.
I think you’re not aware of the AI making up a case name from whole cloth that I am talkimg about? Because that’s not misremembering, it’s exactly what you would expect unintelligent statistical prediction to come up with.
Have you ever graded free response tests before? I assure you that some people do similar things when pressed to come up with an answer when they don’t know. Often, they know they’re BSing, but they’re still generating random crap that sounds plausible. One of the big differences is that we haven’t told AI to tell us “I’m not sure” when it has high uncertainty; though plenty of people don’t do that either.
It’s totally statistics, but that second paragraph really isn’t how it works at all. You don’t “code” neural networks the way you code up website or game. There’s no “if (userAskedForThis) {DoThis()}”. All the coding you do in neutral networks is to define a model and training process, but that’s it; Before training that behavior is completely random.
The neural network engineer isn’t directly coding up behavior. They’re architecting the model (random weights by default), setting up an environment (training and evaluation datasets, tweaking some training parameters), and letting the models weights be trained or “fit” to the data. It’s behavior isn’t designed, the virtual environment that it evolved in was. Bigger, cleaner datasets, model architectures suited for the data, and an appropriate number of training iterations (epochs) can improve results, but they’ll never be perfect, just an approximation.
But the actions taken by the model in the virtual environments can always be described as discrete steps. Each modification to the weights done by each agent in each generation can be described as discrete steps. Even if I’m fucking up some of the terminology, basic computer architecture enforces that there are discrete steps.
We could literally trace each command that runs on the hardware that runs these things individually if we wanted full auditability, to eat all the storage space ever made, and to drive someone insane. Have none of you AI devs ever taken an embedded programming/machine language course? Never looked into reverse engineering of compiled executables?
I understand that these things work by doing these steps millions upon millions of times, but there has to be a better middle ground for tracing these things than “lol i dunno, computer brute forced it”. It is a mixture of laziness, and unwillingness to allow responsibility to negatively impact profits that result in so many in the field to summarize it as literally impossible.
But the actions taken by the model in the virtual environments can always be described as discrete steps.
That’s technically correct, but practically useless information. Neural networks are stochastic by design, and while Turing machines are technically deterministic, most operating systems’ random number generators will try to introduce noise from the environment (current time, input devices data, temperature readings, etc). So because of that randomness, those discrete steps you’d have to walk through would require knowing intimate details of the environment that the PC was in at precisely the time it ran, which isn’t stored. And even if it was or you used a deterministic psuedo-random number generator, you’d still essentially be stuck reverse engineering the world’s worse spaghetti code written entirely in huge matrix multiplications, code that we already know can’t possibly be optimal anyway.
If a software needs guaranteed optimality, then a neural network (or any stochastic algorithm) is simply the wrong tool for the job. No need to shove a square peg in a round hole.
Also I can’t speak for AI devs, in fact I’ve only taken an applied neural networks course myself, but I can tell you that computer architecture was like a prerequisite of a prerequisite of a prerequisite of that course.
There’s a wide range of “explainability” in machine learning - the most “explainable” model is a decision tree, which basically splits things into categories by looking at the data and making (training) an entropy-minimizing flowchart. Those are very easy for humans to follow, but they don’t have the accuracy of, say, a Random Forest Classifier, which is exactly the same thing done 100 times with different subsets.
One flowchart is easy to look at and understand, 100 of them is 100 times harder. Neural nets are another 100 times harder, usually. The reasoning can be done by hand by humans (maybe) but there’s no regulations forcing you to do it, so why would you?
It’s true that each individual building block is easy to understand. It’s easy to trace each step.
The problem is that the model is like a 100 million line program with no descriptive variable names or any comments. All lines are heavily intertwined with each other. Changing a single line slightly can completely change the outcome of the program.
Imagine the worst code you’ve ever read and multiply it by a million.
It’s practically impossible to use traditional reverse engineering techniques to make sense of the AI models. There are some techniques to get a better understanding of how the models work, but it’s difficult to get a full understanding.
deleted by creator
Tensorflow has some libraries that help visualize the “explanation” for why it’s models are classifying something (in the tutorial example, a fireboat), in the form of highlights over the most salient parts of the data:

Neural networks are not intractable, but we just haven’t built the libraries for understanding and explaining them yet.
I’d have to check my bookmarks when I get home for a link, but I recently read a paper linked to this that floored me. It was research on visualisation of AI models and involved subject matter experts using an AI model as a tool in their field. Some of the conclusions the models made were wrong, and the goal of the study was to see how good various ways of visualising the models were — the logic being that better visualisations = easier for subject matter experts to spot flaws in the model’s conclusions instead of having to blindly trust it.
What they actually found was that the visualisations made the experts less likely to catch errors made by the models. This surprised the researchers, and caused them to have to re-evaluate their entire research goal. On reflection, they concluded that what seemed to be happening was that the better the model appeared to explain itself through interactive visualisations, the more likely the experts were to blindly trust the model.
I found this fascinating because my field is currently biochemistry, but I’m doing more bioinformatics and data infrastructure stuff as time goes on, and I feel like my research direction is leading me towards the explainable/interpretable AI sphere. I think I broadly agree with your last sentence, but what I find cool is that some of the “libraries” we are yet to build are more of the human variety i.e. humans figuring out how to understand and use AI tools. It’s why I enjoy coming at AI from the science angle, because many scientists alreadyuse machine learning tools without any care or understanding of how they work (and have done for years), whereas a lot of stuff branded AI nowadays seems like a solution in search of a problem.
please let us know if you find the article, it sounds fascinating!!
I got you.
Link to a blog post by the paper’s author that discusses the paper (it has many links to interesting stuff. I was skeptical of it when I first found it, given that the one line TL;DR of the paper is “black-boxing is good actually”, but it thoroughly challenged my beliefs): https://scatter.wordpress.com/2022/02/16/guest-post-black-boxes-and-wishful-intelligibility/
Link to a SciDB version of the academic paper (SciHub is dead, long live SciDB): https://annas-archive.gs/scidb/10.1086/715222
(DiMarco M. Wishful Intelligibility, Black Boxes, and Epidemiological Explanation. Philosophy of Science. 2021;88(5):824-834. doi:10.1086/715222)
thank you!
Wow that is sick
This whole “we can’t explain how it works” is bullshit
Mostly it’s just millions of combinations of
y = k*x + mwithy = max(0, x)between. You don’t need more than high school algebra to understand the building blocks.What we can’t explain is why it works so well. It’s difficult to understand how the information is propagated through all the different pathways. There are some ideas, but it’s not fully understood.
??? it works well because we expect the problem space we’re searching to be continuous and differentiable and the targetted variable to be dependent on the features given, why wouldn’t it work
The explanation is not that simple. Some model configurations work well. Others don’t. Not all continuous and differentiable models cut it.
It’s not given a model can generalize the problem so well. It can just memorize the training data, but completely fail on any new data it hasn’t seen.
What makes a model be able to see a picture of a cat it has never seen before, and respond with “ah yes, that’s a cat”? What kind of “cat-like” features has it managed to generalize? Why does these features work well?
When I ask ChatGPT to translate a script from Java to Python, how is it able to interpret the instruction and execute it? What features has it managed to generalize to be able to perform this task?
Just saying “why wouldn’t it work” isn’t a valid explanation.
But it’s called neural network, and learns just like a human, and some models have human names, so it’s a mini-digital human! Look at this picture that detects things in an image, it’s smart, it knows context!

iTs JusT iF/tHEn 🥴🥴🥴
Everything* is just an on/off switch
* offer does not apply to quantum computing
Also linear algebra and vector calculus
My biggest issue is that a lot of physical models for natural phenomena are being solved using deep learning, and I am not sure how that helps deepen understanding of the natural world. I am for DL solutions, but maybe the DL solutions would benefit from being explainable in some form. For example, it’s kinda old but I really like all the work around gradcam and its successors https://arxiv.org/abs/1610.02391
How is it different than using numerical methods to find solutions to problems for which analytic solutions are difficult, infeasible, or simply impossible to solve.
Any tool that helps us understand our universe. All models suck. Some of them are useful nevertheless.
I admit my bias to the problem space though: I’m an AI engineer—classically trained in physics and engineering though.
In my experience, papers which propose numerical solutions cover in great detail the methodology (which relates to some underlying physical phenomena), and also explain boundary conditions to their solutions. In ML/DL papers, they tend to go over the network architecture in great detail as the network construction is the methodology. But the problem I think is that there’s a disconnect going from raw data to features to outputs. I think physics informed ML models are trying to close this gap somewhat.
As I was reading your comment I was thinking Physics Informed NN’s and then you went there. Nice. I agree.
I’ve built some models that had a solution constrained loss functions—featureA must be between these values, etc. Not quite the same as defining boundary conditions for ODE/PDE solutions but in a way gets to a similar space. Also, ODE/PDE solutions tend to find local minima and short of changing the initial conditions there aren’t very many good ways of overcoming that. Deep learning approaches offer more stochasticity so converge to global solutions more readily (at the risk of overfitting).
The convergence of these fields is exciting to watch.
Deep learning approaches offer more stochasticity so converge to global solutions more readily (at the risk of overfitting).
Yeah, thats a fair point and another appealing reason for DL based methods
well numerical models have to come up with some model that explains how relevant observables behave. With AI you don’t even build the model that explains the system physically and mathematically, let alone the solution.
It is basically like having Newton’s Equations vs an AI that produces coordinates with respect to time (and possibly many other inputs we thought were relevant but weren’t because we don’t know the model) given initial conditions and force fields.
Well, lots of people blinded by hype here… Obv it is not simply statistical machine, but imo it is something worse. Some approximation machinery that happen to work, but gobbles up energy in cost. Something only possible becauss we are not charging companies enough electricity costs, smh.
We’re in the “computers take up entire rooms in a university to do basic calculations” stage of modern AI development. It will improve but only if we let them develop.
Moore’s law died a long time ago, and AI models aren’t getting any more power efficient from what I can tell.
Then you haven’t been paying attention. There’s been huge strides in the field of small open language models which can do inference with low enough power consumption to run locally on a phone.
Yeah, and improvements will require paradigm changes. I don’t see that from GPT.
GPT is not the end all be all of LLMs
Are there LLMs with different paradigms?
GPT is not a paradigm it’s a specific model family developed by openAI. You’re thinking of the transformers architecture. Check out a project like RWKV if you want to see a unique approach.
Honestly if this massive energy need for AI will help accelerate modular/smaller nuclear reactors 'm all for it. With some of these insane data centers companies want to build each one will need their own power plants.
I’ve seen tons of articles on small/modular reactor companies but never seen any make it to the real world yet.
nathanfillionwithhandupmeme.jpg
Moldy Monday!
I wouldn’t say it is statistics, statistics is much more precise in its calculation of uncertanties. AI depends more on calculus, or automated differentiation, which is also cool but not statistics.
Just because you don’t know what the uncertainties are doesn’t mean they’re not there.
Most optimization problems can trivially be turned into a statistics problem.
Most optimization problems can trivially be turned >into a statistics problem.
Sure if you mean turning your error function into some sort of likelihood by employing probability distributions that relate to your error function.
But that is only the beginning. Apart from maybe Bayesian neural networks, I haven’t seen much if any work on stuff like confidence intervals for your weights or prediction intervals for the response (that being said I am only a casual follower on this topic).
One of the better uses I’ve seen involved using this perspective to turn what was effectively a maximum likelihood fit into a full Gaussian model to make the predicted probabilities more meaningful.
Not that it really matters much how the perspective is used, what’s important is that it’s there.
Aka fudge

















{kind=link}