
3·
13 days agoYour scientists were so preoccupied with whether or not they could, they didn’t stop to think if they should
Your scientists were so preoccupied with whether or not they could, they didn’t stop to think if they should

Looking at the example
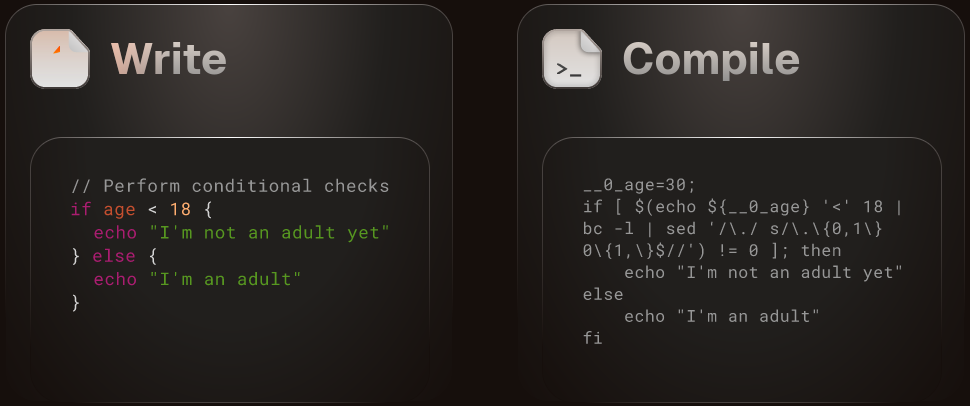
Why does the generated bash look like that? Is this more safe somehow than a more straighforward bash if or does it just generate needlessly complicated bash?

I think he was still on the board after he closed his account, him leaving the board might be much more recent
It’s weird to have something that verbose for using in the shell. I don’t want to use verbose commands when just doing stuff interactively, so I never learn how to really use its features as a concequence. Bash, while it has more footguns, is more readable to me because I’m more familiar with the individual commands. For most programing you spend more time reading it than writing it, but that’s not the case for the shell so there it’s the wrong tradeoff imo.
I do love me a good video game video essay, but I think that a more traditional journalistic format has a lot of strengths when it comes to covering small games. It’s probably true that youtube has replaced a lot of traditional journalism but I think that this is overall bad for the video game echo system.
One thing that I think is missing from the equation is good video games journalism that covers indie games. Video game journalism has never been doing amazing but it’s practically dead now.
Tying discovery to the same platform that you consume things on is really bad, because it always gives that distributor way to much power. Similar story with spotify, but journalism about underground music is at least in a slightly better place.

The problem is that when everyone is using their right to deny access to their works to make people give them money, and there is only so much money you can reasonably spend on entertainment and so on per month, people end up abstaining from a lot of things they could otherwise have taken part in for no extra cost.
I think that the things we pirate have a value: music, movies and games have a value because they are cultural products and vulture is important, software like photoshop has a value because it is a useful tool. Putting up barriers to accessing these things means destroying this value. Having a system where the main way to make money of e.g. music is to paywall it has the “destruction” of a lot of value as its outcome. In some ways streaming platforms like spotify are better in this regard but then that means giving the platform a lot of power over music discovery for example. Spotify doesn’t really do a good job of paying its artists either which is its supposed ethical advantage over piracy.
I think that a system where we should abstain from things that are basically free to reproduce (i.e. things you can pirate) is dumb. There are many movies that I probably wouldn’t pay money to but that I’ve pirated. The companies that own the rights to the movie don’t lose any sale they would have otherwise made but I get whatever enjoyment I get from watching the movie at least, so it’s a net win.
When I pay may bills at the end of the month I also put some money towards paying for things that I’ve pirated that I like, usually with a focus on smaller creators. It doesn’t really feel meaningful to pay for a marvel movie for example. It’s not really a perfect system but neither is artificially limiting the access to digital media.
Since the diffs are tree-sitter based, it’s interesting to think about what a tree-sitter based patch would look like. Probably wouldn’t double as a human and computer friendly format like normals diffs. I suppose that you could create patches that are more robust to the source code changing since it wouldn’t care about linebreaks and maybe you could have it so it doesn’t care if you move code around since you could have it so its going by e.g. what the parent function is and not the line number. I gotta wonder how useful that actually is though.
There is a lot of fanboying in discussions like these, so I understand if you’re weary of that. That said I don’t think static analysis tools are a very good point of comparison for (what I’m assuming that you’re referring to) Rusts ownership system.
While static analysis tools certainly can be useful for some classes of errors, there are types of errors that they can’t catch that the borrowchecker can. This is because the language are built around them in Rust. Rusts lifetime analysis is dependent on the user adding lifetime annotations in certain situations, so since c++ doesn’t have these annotations static analysis tools for c++ can’t benefit from the information these annotations provide.
Furthermore, c++ suffers from being an old language with a lot of features. Legacy features can allow for various loopholes that are hard for a static analysis tool to reason about.
C++ static analysis tools can find errors, but Rusts borrowchecker can prove the absence of errors modulo unsafe code.
That said, I don’t have any good data on how much of a problem this is in practice. Modern c++ with a CI-pipeline doing static analysis and forbidding certain footguns is safe enough for most contexts. Personally, I’m exited about Rust more because I think that it’s a nicely designed language than because of its safety guarantees, but it doesn’t really have the ecosystem support for a lot of things, like gamedev or ui at the moment.
There will be plenty of jobs in c++ in the foreseeable future, so it’s not a bad language to know from that perspective. I don’t know if it’s the most pedagogical language to learn otoh, python is a better language for getting comfortable with the basics, c is better when it comes to learning a (slightly wrong but close enough) mental model of how a computer works under the hood, and there are many better languages to learn if you want to learn good approaches to thinking about problems.
Maybe you are leaning c++ because you want to work on something specific that c++ is primarily used in, and in that case go ahead with that project. I think having something tangible that you want to work on is great when it comes to learning programing and that’s worth more than picking the “best” language. Besides, you can always learn different languages later in your career if you want/have to.
I have a copy that I got from https://github.com/yuzu-mirror/yuzu. Looking at its master branch of the main repo, it has dc94882c9062ab88d3d5de35dcb8731111baaea2, followed by 4 commits related to translation (likely the same as OPs) followed by a couple of commits that only change github urls from yuzu-emu to yuzu-mirror.
deleted by creator
even a small amount of change into an LLM it turns out to radically alter the output it returns for huge amounts of seemingly unrelated topics.
Do you mean that small changes radically change the phrasing of answers, but that it has largely the same “knowledge” of the world? Or do you mean that small changes also radically alter what a llm thinks is true or not? If you think the former is true, then these models should still be the same in regards to what they think is true or not, and if you don’t then you think that llms perception of the world is basically arbitrary and in that case we shouldn’t trust them to tell us what’s true at all.
Well if we have a reliable oracle available for a type of questions (i.e. Wolfram Alpha) why use an llm at all instead of just asking the oracle directly
The problem isn’t just that llms can’t say “I don’t know”, it’s also that they don’t know if they know something or not. Confidence intervals can help prevent some low-hanging fruit hallucinations but you can’t eliminate hallucinations entirely since they will also hallucinate about how correct they are about a given topic.
Sometimes I’ll solve a computer problem for someone in an area that I know nothing about by just googling it. After telling them that all I had to do was google the problem and follow the instructions they’ll respond by saying that they wouldn’t know what to google.
Just being experienced at searching the web and having the basic vocabulary to express your problems can get you far in many situations, and a fair bit of people don’t have that.
Multiple cursors are a lot better than :s for you standard search and replace, unless you have a really big file at which point helix gets to slow (which isn’t that common) but there are a lot of other stuff you can do with ex commands.
I use :make pretty often, vim ships with the ability to parse a lot of compiler/linter outputs out of the box so if you tell it which one with :compiler you get build errors in the quickfix list. I also use :grep a lot. You can do <space>/ to grep in helix but I often find that I want to add command line options to only search in specific directories or for specific file types (we have a large codebase at work). Being able to filter results with :Cfilter, and being able to go back to old quickfix results with :colder is also really nice. Finally, you can use :cdo to apply ex commands to stuff you’ve matched in the quickfix list.
As an example, if you get a build error because you’ve renamed a variable in one file but not the places it gets referenced in other files, you can :make to get the build errors in you quickfix list, :Cfilter to narrow it down to only that specific class of error if needed and then do :cdo s/oldName/newName/g to rename the variable in all places that cause errors. You can then go back to the list of all errors with :colder and handle other errors in another way if needed.
I’ll have to admit that I don’t do this that often so honestly I wouldn’t lose out on that much switching to helix (after it gets proper plugin support and someone makes a decent replacement for the fugitive git plugin) but I would feel less powerful not knowing that I have those tools up my sleave lol.

I think that it’s quite bad if Microsoft puts peoples family photos on their servers without the user realizing it. That’s not a niche privacy nerd sentiment, I think that a lot of people would find that creepy. Having the option easily available can be really good for a lot of non-techy people but it should be very clear what stays on your computer and what doesn’t, and how to keep something private if you want to, which I’m not sure that it is if Microsoft quietly backs up Documents, Pictures etc.