you get exactly what you need. Your software makes a very specific request, and that’s what you get.
Complex queries are easily handled. In a standard rest API, you might make multiple fetch requests. One call to get all the users, another call to find a specific user’s data based on their ID. GraphQL can do that with a single call.
Why it sucks:
it’s a lot of boilerplate to set up on both sides. The client needs to know exactly what they want. I found myself having to teach multiple types of engineers (those implementing the middleware, those receiving the data) how to approach.
You need to understand the schema, the logic, how to write queries. Rest Api, you make the call and you get a response that you can easily convert into a data object and manipulate it in your own language. To use GraphQL effectively, you need to know how to do that “the GraphQL way”.
The way the data is exposed is kinda a security risk. (But so is Rest APIs in general). I feel like there’s more security through insecurity in rest Api, as each endpoint is its own thing. But graphQL has one single endpoint. It all depends on how it’s built.
To better explain the latter - I had to create TWO graphQL endpoints (one for clients and one for higher privileges) and it was a pain to manage. But I spent a LOT of mental resources organizing that to ensure both types of customers only got exactly what they should get. Not to say it would have been easier with rest APIs, but it would have been easier to think about.
For the record: I like graphQL as a concept. Just the complexities far outweigh the benefits my team is getting. It was like we spent $100k of dev resources to save $500 a month off our AWS bill.

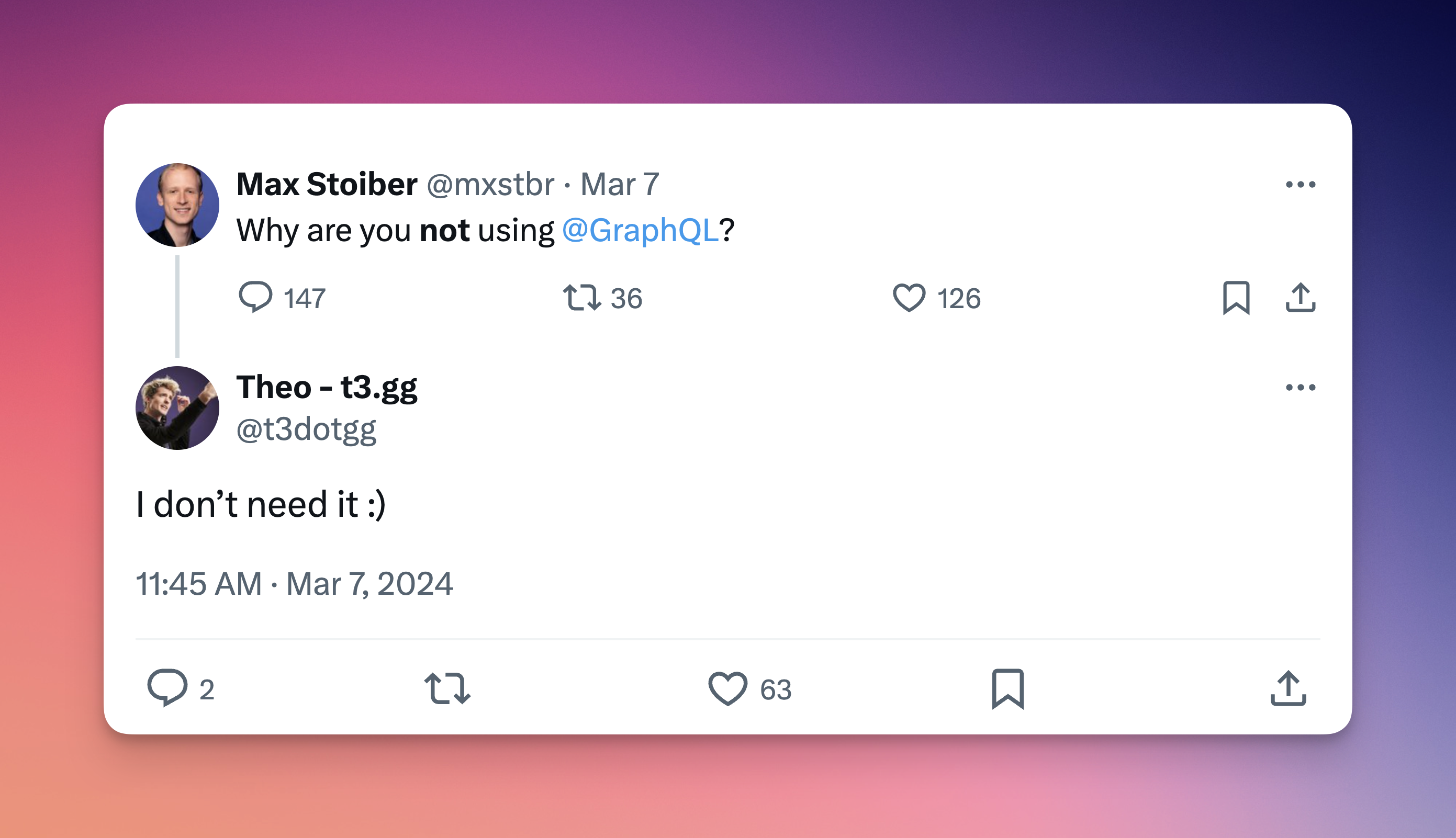
Why it’s good:
you get exactly what you need. Your software makes a very specific request, and that’s what you get.
Complex queries are easily handled. In a standard rest API, you might make multiple fetch requests. One call to get all the users, another call to find a specific user’s data based on their ID. GraphQL can do that with a single call.
Why it sucks:
it’s a lot of boilerplate to set up on both sides. The client needs to know exactly what they want. I found myself having to teach multiple types of engineers (those implementing the middleware, those receiving the data) how to approach.
You need to understand the schema, the logic, how to write queries. Rest Api, you make the call and you get a response that you can easily convert into a data object and manipulate it in your own language. To use GraphQL effectively, you need to know how to do that “the GraphQL way”.
The way the data is exposed is kinda a security risk. (But so is Rest APIs in general). I feel like there’s more security through insecurity in rest Api, as each endpoint is its own thing. But graphQL has one single endpoint. It all depends on how it’s built.
To better explain the latter - I had to create TWO graphQL endpoints (one for clients and one for higher privileges) and it was a pain to manage. But I spent a LOT of mental resources organizing that to ensure both types of customers only got exactly what they should get. Not to say it would have been easier with rest APIs, but it would have been easier to think about.
For the record: I like graphQL as a concept. Just the complexities far outweigh the benefits my team is getting. It was like we spent $100k of dev resources to save $500 a month off our AWS bill.